
SIEM ist ein sehr komplexes Thema, bei dem man nach und nach immer weiter in die Tiefe geht. Doch wie findet man einen Start in das Thema?
Im ersten Schritt ist eine Konsolidierung der Logdateien bzw. die zentrale Speicherung dieser notwendig.
Vor der Praxis steht dabei jedoch die Theorie oder besser gesagt die Frage, was muss technisch und organisatorisch an Vorbereitungen getroffen werden und was sind die Anforderungen.
Allgemeine Anforderungen und Festlegungen
Stellt man sich dem Thema SIEM muss einem gleich bewusstwerden, dass hierbei sehr viele Daten gesammelt werden.
Hierzu eine kleine Beispielrechnung, die für einen Kunden von S&L erstellt wurde:
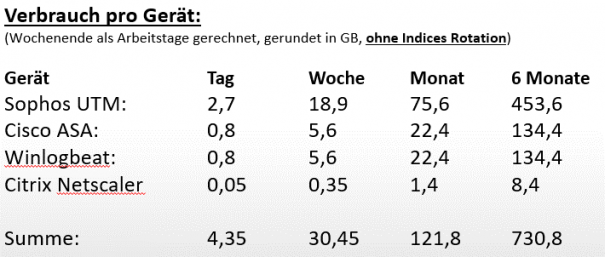
Abbildung 7: Beispielrechnung Datenaufkommen
- Entscheidend sind am Anfang unter anderem folgende Festlegungen:
- Was soll und kann in welcher Tiefe an Informationen gesammelt werden?
- Wie lange sollen oder müssen die Informationen aufbewahrt werden?
- Wo sollen und dürfen die Daten abgelegt werden?
Ohne an dieser Stelle genauer darauf einzugehen, sind hierbei auch rechtliche Vorgaben zu berücksichtigen.
Unsere Techniker können daraufhin Empfehlungen für die Hardwareausstattung bei einem OnPremise Betrieb aussprechen. Bei einem Cloud Betrieb können die anfallenden Kosten kalkuliert werden. Beides ist jedoch immer nur als grobe Tendenz anzusehen. Im Vorfeld ist es überaus schwierig genau zu definieren, wie viele Daten anfallen werden. Hier gibt es zu viele Faktoren, die die Datenmenge beeinflussen können (Systeme, Mitarbeiteranzahl, Verwendung der Systeme).
Gesetzliche Fragestellungen können wiederum in Verbindung mit den Kollegen der S&L ITCompliance GmbH geklärt werden.
Umsetzung
Nachrichten werden von Logstash entgegengenommen („Input“) verarbeitet und wieder ausgegeben („Output“). Hier ein kleiner Überblick, inwiefern die Techniker / Entwickler tätig werden. Logstash kann sehr viele verschiedene Quellen bzw. „Inputs“ verarbeiten. Eine Übersicht findet man hier: https://www.elastic.co/guide/en/logstash/current/input-plugins.html
Über Pattern Files werden die Nachrichten verarbeitet.

Viele der Pattern Files liefert Logstash schon von Haus aus.
Mittels Grok-Filtern werden die Nachrichten klassifiziert und verarbeitet und für Elasticsearch ausgegeben:


Prinzipiell muss man für jedes abzufragende System eine Einrichtung, wie oben ersichtlich, vornehmen. Fehlen Pattern-Files, müssen diese erstellt werden. Mittels der Grok-Filter werden die unstrukturierten Daten dann für Elasticsearch aufbereitet.
Neben Grok gibt es auch noch weitere Möglichkeiten, wie bspw. Dissect um die Daten aufzubereiten.
An dieser Stelle möchten wir uns jedoch bei der Betrachtung hierauf beschränken.
Weiteres Vorgehen
Ob man nun erst alle Systeme betrachtet und alle Logs konsolidiert und erst daraufhin mit der Umsetzung von Auswertungen mittels Kibana beginnt, oder ob man hier einzelne Pakete nach Priorität schnürt, ist letztendlich eine Frage der Anforderung.
Wir empfehlen hier, die wichtigsten Systeme anzugehen und auch direkt auszuwerten, um frühestmöglich bereits in die Ereigniserkennung eintreten zu können. Beispielsweise ist es bereits ein enormer Mehrwert, wenn Events der Firewall ausgewertet werden und hier Daten über einen langen Zeitraum zur Verfügung stehen, sowie diese auch ausgewertet werden können, falls es zu einem Angriff/Angriffsversuch kommt.
Im nächsten Artikel werden wir direkt aus der Praxis bei einem unserer Kunden berichten. Was wurde umgesetzt, welche Ergebnisse und Mehrwerte konnten erzielt werden und wie ist die Erfahrung des Kunden.